作者:蓬岸 Dr.Quest
知乎文章编号:372200102
创建于:2021-05-13 9:18:16
修改于:2021-05-14 7:03:23
此文是我在由科罗拉多大学博尔德分校 媒介考古实验室 x (民族+科技)微基金 (MAL x (Race + Technology) Micro-Grants)支持的 avant la lettre: 中文文字考古:onebigear/avant_la_lettre_public_copy 活动中的演讲稿,原稿“Bring Chinese Characters into computer”为英文,主要面向非中文母语的听众,此译文保留了原稿大部分内容,仅对部分语言做了调整。
大家好,感谢大家参加我的在线演讲,我今天将会分享一个中国的计算机文化中时常讨论的话题,即“让电脑处理中文”。在这个演讲中,我将展示中国电脑工程师和业余爱好者社区在利用计算机技术处理中文信息方面的一系列努力。
首先允许我自我介绍一下,我是一名软件工程师,同时我也是独立的媒体研究者。之前十多年中我大多数时间我都住在加拿大温哥华,我在2019年的时候回国开展了一系列研究项目,希望能够以此更深入的了解中国本土电脑爱好者社群。
在2003年和2004年的时候,我是一个软件汉化爱好者,我那时候还是高中生,说起来也是18、19年之前的事情了。我当时把一些英文软件翻译成中文,主要是是运行在Palm OS上的移动应用程序,希望国内的用户能够更方便的使用这些软件。
在互联网档案馆中,中国Palm用户组(CnPUG)的网页存档里还可以找到我的一些作品。
我当时的网名是 Dr.Quest,来自于动画片“Jonny Quest”中的一个角色。大家可以看到我当时汉化过的一些软件,比如GreyPaint和EasyCalculator等等。
对移动操作系统的中文功能的研究,是我研究中文语言处理的起点。除了PalmOS,我还研究过Windows CE系统。相比Palm OS而言Windows CE对中文的支持要好得多,因为它有很多对中文处理非常重要的功能,比如说对Unicode和TrueType的支持。我的在移动平台上的这些个人经验,也构成了中国爱好者社区历史的一部分。

当然,今天我的演讲有一些局限性:一方面是我目前的研究主要关注于中国大陆的实践,这不仅因为我是在中国大陆长大的,也因为我前面所提到的,我是中国大陆软件汉化社群的一员。
因此,我对中国大陆的情况,包括技术标准、用户社区和技术政策都更加熟悉。相比之下,香港和台湾的情况对我来说就比较陌生。因此,我目前的研究和今天的演讲将侧重于中国大陆的实践。
另外,与许多侧重于官方和学术机构的研究不同,我的研究完全出自我的个人兴趣。所以我对中文编码的研究将从爱好者的视角出发,去关注那些非正式的场合下,人们是如何使用电脑的。也因此,我的研究更侧重于微型计算机,特别是家用计算机的情形,而无法提供太多关于大型主机的信息。
据我所知,1980年代之前,在中国就已经有一些大型机可以配合中文电报设备处理汉字。但是由于这些文件和资料只能从一些政府部门和研究机构获得,我目前还没有足够的资料对这些用例开展研究。
在我看来,对于汉字的使用者来说,汉字作为宝藏的同时也带来麻烦。由于我的母语是普通话,所以这种感觉直到我搬到加拿大后才变得明显,在加拿大期间,通过汉语学习者和非汉语母语的汉字使用者的接触,我对汉字的作用有了一些不同方面的了解。
相比计算机世界里最常用的英语,使用汉字表达的语言有着更高的信息密度。有一项来自Twitter的研究显示,推特上日本用户的推文比英语用户更加简短。因为日语中使用了汉字,因此也具有更高的信息密度,表达相同意思的句子会更短。
Twitter的博客原文:Giving you more characters to express yourself
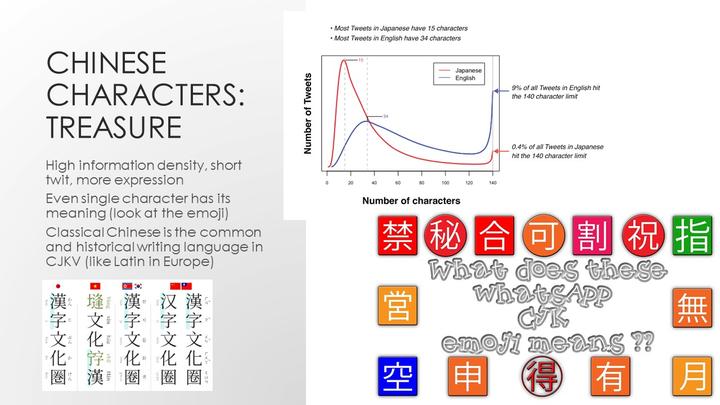
同时,即使是单个汉字也有着丰富的表义。一个很好的例子就是表情符号(Emoji)。比如“禁”表示不要做某事,“合”意味着更联合或合作,“割”意味着分离或是交易,“空”意味着空闲或空间等等。
文言文是东亚地区共同的历史性语言,是中国、日本、韩国和越南学者间通用的书面语。就像欧洲的拉丁语一样。在中国,中学毕业的学生就已经具备了阅读古汉语的基本知识。这意味着他们可以阅读相当多的历史档案,这其中不仅包括中国的文献,也包括相当数量的韩国、日本和越南古籍。
汉字也给它的使用者带来了不少麻烦,汉字数量众多,清朝的官方字典《康熙字典》有47000多个汉字。而广泛收录中文和日文语汇的《大汉和辞典》有超过5万个汉字。数量巨大的汉字意味着陡峭的学习曲线,学习者需要花费数年的努力来学习如何阅读和书写汉字。
在中国大陆,三年级或四年级的学生可以认读大约2500个,书写大约1600个汉字:教育部公布新课程标准 小学生会写汉字减400个。在使用汉字较少一些的日本,六年级学生可以认读大约1000个汉字。

此外,正如这些幻灯片里显示的那样,汉字有很多笔画。因此,相比拉丁字母,需要更多的像素才能清楚地显示汉字。这往往对软件、硬件开发者都提出更高的挑战,一个例子是90年代中后期开发的Palm Pilot掌上电脑,由于是一款低功耗的移动设备,它的硬件资源非常有限,屏幕分辨率只有160x160像素,为了在掌上电脑上清晰的显示汉字,工程师们制作了10x10像素点阵字体,这个规格可能是广泛使用的汉字字体中最小的一种了。
汉字的数量如此之大,因此可以想见电脑处理汉字时会消耗大量的内存。我本人很喜欢1980年代的Commodore 64电脑,当我住在加拿大的时候,有很多爱好者向我展示了这款电脑上丰富的游戏软件。这些游戏展示了Commodore 64的强大图像和声音功能,但很遗憾的是它并不能处理中文。
事实上,不仅仅是Commodore 64,大多数典型的8位计算机系统在没有经过特别改造的情况下都不能处理中文,因为8位处理器通常无法直接支持较大的内存空间。
当然在80年代时已经有一些更先进,也更昂贵的16位个人电脑了,比如运行PC-DOS的IBM PC就可以支持640k内存,这个容量远远超过大多数流行的8位电脑,对于当年的电脑工程师来说算得上是“海量”了。

有一个关于比尔·盖茨的都市传说,就是盖茨曾经说过:“没有人用得着超过640K的内存”。然而,对于用计算机处理中文这件事情来说,640K内存仍然是捉襟见肘的,在后面我会和大家一起计算一下显示中文字符需要多少存储空间。
中国的字符标准在很大程度上受到日本字符标准的影响。早在20世纪70年代,日本就已经具备了发达的微电子工业,因此在东亚,日本也是最早成功开发支持汉字的微型电脑的国家。
为了节省有限的硬件资源,70、80年代开发的所有汉字标准都只选取了数万汉字中较为常用的一部分字符。日本最初的JIS字符系统只有6800多个字符,该字符集是在1978年标准化的。而中国大陆GB标准与日本JIS标准很相似,它比日本标准的字符更多一些,有7400多个字符。

上面这张表显示了不同的字符集包含多少汉字,我们可以看到所有这些字符集都将汉字分为两个子集,或者说两个“级别”。一级汉字是最常用的字符,而二级字符则稍微少用一些,但与字典中数以万计的字符相比,即使是二级汉字仍然要比没有收录的那些字符更常用。
在表中最早出现的标准是日本的JIS,只包含6800多个字符,稍后出现的是中国大陆标准,即GB标准,包含7400多个字符;而作为台湾地区行业标准的繁体字符集Big5标准化的时间较晚,是1984年,但包含的字符更多,有13000多个字符。
限制字符集的字符数是为了节省内存,那么实现汉字的显示需要多少内存容量呢?让我们来计算一下:

16×16像素是最常用的中文点阵字体的尺寸之一,单色像素每个像素只要一个比特,因此每个字符就是16×16 = 256比特,也就是32字节(一个字节有8个比特)。
要把 GB2312 中的 7000 多个字符的点阵全部存储在内存里,需要 1.9Mbit (1.9兆比特),换算一下就是232KByte(千字节),而一般的 8 位计算机,如 Apple IIe 或 Commodore 64,都只有 64KByte 内存,这样的内存容量是无法装下完整的GB2312汉字点阵的。
即使是装满640KB内存的IBM PC XT电脑,当装载全部GB2312汉字字体之后,可以用来运行程序的内存也会大打折扣,所以许多早期的中文计算机方案都是使用带有ROM的扩展卡,在日语或简体中文系统中,第一级字符使用一兆比特,第二级使用另一兆比特,所以2Mbit的ROM芯片可以包含所有字符。
用同样的方法,我们可以计算一下Big5繁体中文系统需要多少内存容量,大概就是2Mbit可以包括一级字符,4Mbit可以包括该标准下的所有字符。
让我们看看下一张幻灯片,这台电脑是市场上能买到的最早支持中文的微型电脑,它叫MicroProcessor II-C,中文名叫“小教授二号”,它是由台湾地区的Multitech开发的,这个品牌大家可能听上去会有点陌生,实际上它就是目前最大的PC制造商之一Acer(宏碁)成立初期的品牌。作为80年代上半叶推出的电脑,它在一定程度上与Apple II兼容:可以运行Apple II图形模式下的程序,但无法兼容Apple II文本模式的程序。

与我们之前的计算不同的是,这台电脑只安装了额外的64KB ROM就可以显示22000个汉字。它应当使用了一种相当精巧的方法去节约字库空间。具体的细节我还不是太清楚,我的猜测这款电脑可能仅仅在ROM种存储了偏旁部首的点阵,然后在显示的时候在通过软件程序将它们组合成完整的汉字,但我并没有很确凿的证据证明这一点。
另一个值得一提的是ZD-2000中文电脑和终端。这台机器既可以作为一台8位微机独立工作,也可以作为大型机的终端。这张照片拍摄于20世纪80年代初的石家庄陆军指挥学院,显示出这台计算机是由军队开发的。
ZD-2000电脑的基础是NEC的PC-8001电脑。当时NEC已经成功开发了几款可以显示日语汉字的计算机,成为中国的工程师开发本土中文电脑的重要参考。

根据一些资料,在这台电脑上就采用了两级汉字的设计,最常用的一级字符存储在ROM中,这意味这款机器可以非常快速的显示常用的字符;而不太常用的二级字符则存储在较慢的软盘中。尽管如此,由于这台电脑的军方背景,许多技术细节仍然没有公开,我并不能找到任何这款电脑的模拟器或当时的应用软件。
那么有没有可能直接用不加改造的日文电脑系统处理中文呢?这就要看情况而定了,JIS标准有6000个汉字,能够表达的意思已经相当丰富了,但是它仍然缺少一些在中国最常用的字符:比如“办法”,“垃圾”都是中文的常用词,JIS字符集没有这些字符,只能使用不合规范但相似的字符来代替,就像幻灯片中显示的那样。这种变通方法在工业设备中很常见,因为许多工业设备是直接从日本进口的,没有专门的中文软件。

另一种情况是消费类电子产品,例如这张照片里MD机的线控遥控器,这个遥控器只有日文和英文版本,其中日文版本在中国非常流行,因为可以通过日文汉字来显示中文歌名。
我这里做一个小演示来展示一下用于MD线控或和类似的电脑设备的软件: GB-Shift JIS转换器,软件的标题栏显示它是2002年的一款软件,是为Windows 98系统开发的。我们看到这个软件在将GB编码的简体中文转换成Shift-JIS编码时,一些字符从简体字转换为繁体字,一些字符被替换为相似但不相同的字符。
虽然因为这些繁体字和错别字的存在,这种没有中文支持的日文系统不能用于处理正式的公文,但对于业余爱好者或一些文字内容不那么重要的工程场景下,这种技巧曾经在中文世界里广泛的使用。
使计算机支持中文的方案大概可以分为两类,即基于硬件的方案和基于软件的方案。
目前国内销售的大多数电脑都使用软件来支持中文,它们的硬件部分与在其他国家销售的型号都没有明显的不同(通常只有配置上的增减和印有汉字的键盘)。然而直到在20世纪90年代末之前,以“汉卡”为代表的硬件解决方案都没有完全被淘汰。
比如说我们刚才谈到的两款电脑,小教授二号和ZD-2000,都是使用硬件解决方案来支持中文的。这种硬件通常是安装在主板上的ROM芯片,其中存储了中文字体和输入法等处理中文内容需要的软件,当然有些时候这个ROM芯片不是直接焊在主板上,而是通过扩展卡的形式安装在主板上的特定插槽里。

跟基于软件解决方案相比,硬件方案通常工作速度更快,使用更少的CPU和内存资源。但它在安装和扩展方面比较困难:通常用户需要打开机箱并将汉卡插入扩展槽,有时还需要设置跳线和驱动程序,因此安装汉卡通常需要用户对电脑硬件比较了解,或是由专业人员来完成。另外,有些电脑没有扩展槽,例如一些老式Macintosh电脑,这样也就没法通过安装汉卡的形式来支持中文了。
软件解决方案通常以中文软件套装的形式出售,这种软件套装一般都会同时包括中文字体和输入法,有时也会捆绑汉化版的字处理软件。它的启动速度比较慢,因为从软盘或硬盘加载字体到内存里需要不少时间。
相比硬件汉卡,汉字软件一般都需要使用更多的CPU资源和内存空间,有些时候软件中文系统也会挑显卡,比如大多数中文系统都不支持早期IBM PC使用的CGA显卡,因为CGA显卡的分辨率很低,显示的中文字符很有限。在80、90年代,实用的中文电脑通常需要配备HGC(Hercules)单色显卡,或VGA彩色显卡。
相比硬件汉卡来说,中文软件使用起来更加容易,很多时候只要插入磁盘并启动电脑,中文环境就会在启动的过程中自动加载。同时中文系统软件通常比硬件汉卡要便宜得多。特别是盗版软件在20世纪90年代相当普遍,因此对中国的个人用户来说,中文系统几乎是免费的。
软件中文系统开始流行是在90年代初IBM AT级别的兼容电脑(比如浪潮0530和东海0530系列)逐渐普及之后,典型的IBM AT兼容机使用286 CPU,1M内存和1.2M高密度5英寸软驱。在286和更高级的x86电脑上,一些中文系统可以将字体、输入法等较占内存的资源加载到640K以上的内存空间(通常称作HMA或高内存区 - High Memory Area),省出宝贵的640K常规内存给用户的应用程序使用。
这张表格展示了不同计算机平台的流行度,和相应的中文解决方案。
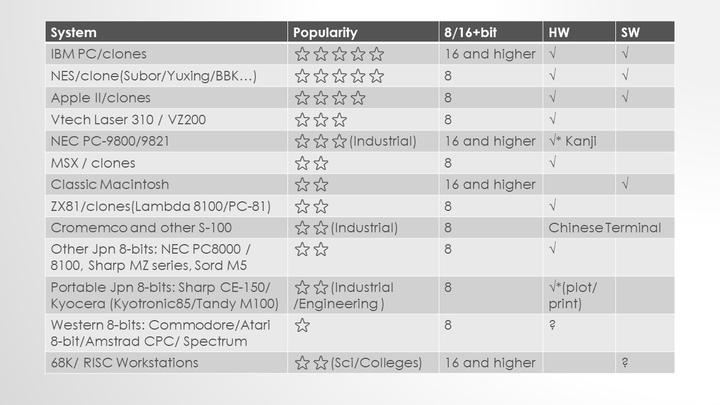
IBM PC的兼容机在中国最为普遍,它们使用16位8086、8088或更先进的CPU,运算速度较快,也支持比较大的内存容量,同时有许多不同的厂商提供多种类型的的中文硬件和软件。
在20世纪90年代,基于红白机开发的学习机作为低成本的家用电脑也非常流行,90年代中后期期的学习机比作为其开发原型的红白机和大多数8位电脑要强大得多,在这次演讲的后面,我将演示步步高学生电脑模拟器,来展示这类电脑的运行状况。
包括小教授二号在内,带有中文支持的Apple II克隆机在中国也很流行,我会演示中国大陆最流行的Apple II克隆机CEC-I中华学习机来向各位演示中国Apple克隆机的功能。
NEC PC-98系列是为日文环境开发的计算机,它们曾作为制造业设备大量进口到中国。使用Zilog Z-80处理器的8位家用电脑,如Vtech(Laser 310)和ZX81克隆机都有若干不同类型的硬件中文解决方案,但都没有像汉化Apple II克隆机那样流行。使用68K处理器的苹果Macintosh从OS 6.0.7开始加入中文支持,但是Macintosh对于当年的大多数国人来说都太贵了。Unix工作站从90年代后期开始在X-Window中加入中文支持,但这些工作站同样非常昂贵,因此只在科研和教育领域得到少量应用。
演示1:CEC-I
中华学习机——CEC系列是Apple IIe的仿制型。它们主板上安装有包括 1 级和 2 级 GB2312 字符的 ROM芯片以及相关的软件,因此它的中文系统是一种“板载汉卡”式的硬件方案。CEC-I是这个系列的第一个型号,从1987年开始大量生产,并持续到90年代初,这些电脑在教育系统中曾被广泛使用。
演示2:小霸王SB486
小霸王SB486系列是最流行的基于仿制红白机的家用电脑之一,它配有IBM PC相同键位的键盘。这款机型出现于20世纪90年代出现时大容量Mask ROM已经较为便宜,因此它的软件都存在一张4Mbit的硬件卡带(学习卡)里,我们现在能找到若干个不同版本的学习卡。它有一个并行端口,可以从字处理软件中打印文稿,但这个型号不支持软驱。
演示3: HHBIOS2.13
“2.13”是由吴晓军开发的CCDOS 2.10的改进版,“2.13”这个数字延续自它的前身“2.11”和“2.12”。在2.13发布之后,吴晓军选择用字母来标记其后续的更新。我在这个演示中使用的是2.13I,这是2.13的第9次更新。
2.13使用了DOS外挂软件中文解决方案中最常见的技术路径,即接管了BIOS中断10h来管理汉字显示,中断16h用于键盘输入,中断17h用于打印输出。这种做法也是在VESA VBE和直接写屏等技术流行之前的事实标准。
2.13设计的非常优秀,它即可以在老式的CGA显卡上工作,也可以和后来成为PC事实标准的VGA显卡一起工作。大多数英文软件不需要做任何改动就可以配合2.13系统处理中文信息。在这个演示中,我会展示2.13和汉化版WordStar。
演示4:UCDOS 6.0
UCDOS 6.0是20世纪90年代末的产品,它是一款非常强大的中文软件套装,提供更“智能”的中文拼音输入法,并且捆绑了流行的文字处理软件金山WPS,以及类似Windows 3.1的图形界面UCSHELL和所见即所得风格的表格软件UCTAB。
演示 5:BBGCDOS
步步高软驱一号是由任天堂红白机衍生而来的最强大的“学习机”型家用电脑之一,它内置了512KB 内存,因此可以容纳全部一级和二级GB2312点阵字体。同时它还内置了3.5英寸高密度软驱,完全兼容PC-DOS的1.44MB格式。它还有自己的 “WPS”文字处理软件,与UCDOS不同的是,这个“WPS”并不是由金山公司的产品,而是由清华大学的唐瑞春教授专门为这类学习机开发的。步步高的WPS可以打开和创建金山WPS格式的文件,因此使用软盘可以无障碍的在IBM PC兼容机和步步高学生电脑之间交换数据。
正如前面的演示中展示的那样,从80年代末的CEC-I到90年代末的UCDOS和步步高学生电脑,中文计算机系统已经发展到一个相当成熟的阶段,也为中文使用者提供了能够显著提高生产力的数字化工具。
但是上面这些计算机系统仍然有一个明显的限制,就是它们所遵守的GB2312标准。GB2312字符集包含6000多个字符,但仍不能涵盖所有用途。特别是GB2312中缺少一些人名常用的字符,如 "堃 "和 "镕"。
在20世纪90年代末,GB编码缺字成为一个特别棘手的问题。对新闻记者来说这一点尤其重要,因为如果他们的电脑到1998 年还在使用基于GB2312标准的中文系统,那么这些电脑就无法正确显示中国总理的名字:朱镕基先生的名字中的 “镕”并不包括在GB2312中。
因此1995年GB2312有了一个扩充版本,即GBK,含义为“国家-标准-扩展”,它包括21000多个汉字和800多个符号。微软从Windows 95开始支持GBK标准。随后中国大陆的电脑使用者开始陆续将他们的操作环境从基于DOS的系统(如UCDOS)升级到中文Windows 95以支持更加强大和实用的GBK编码。
接下来的两个演示将显示其区别。第一个演示使用微软专门为简体中文用户开发的Windows 3.1升级版Windows 3.2完成。而另一个演示将展示支持GBK的Windows 95。
演示6:Windows 3.2/UserFont.exe
我的Windows 3.2模拟器中安装了WPS 97,它是金山WPS的Windows版本。假设我是一个新闻记者,想把今天的新闻标题输入电脑,但是我无法完成这个任务,因为Windows 3.2只支持GB2312编码。
Windows 3.2 提供了“造字程序”,我可以创建自定义字符,并这个字符添加到我的系统中。但是,我把这个字符的编码指定为造字区专用的 "AAA1",由于它不是标准化的代码,所以它只能供我个人使用,不能用于文档交换,而其他人的计算机仍然不能显示这个字符(有一些造字档在一些企业和政府部门见小范围通用,但都未广泛使用)。
“造字程序”在较新的Windows版本中仍有提供,称为“Private Character Editor”,即“TureType 造字程序”,顾名思义,新的造字程序并不像Windows 3.2提供的那样使用点阵字体,而是基于TrueType矢量字体技术。
将字符添加到自定义字体中是一项相当辛苦的工作,所以如果我有很多GB2312以外的字符需要使用,我需要在造字上花费不少时间。
演示7:Windows 95 / GBK
因为Windows 95可以支持 GBK,所以相比Windows 3.2的情况要好得多,我在 Windows 95 上输入同样的新闻标题就没有任何障碍。
但是,Windows 95中只有宋体和黑体支持GBK,这是中文中最常用的有衬线和无衬线字体,像类似手写字体的楷体和较细的衬线字体仿宋体仍然只支持GB2312。
在一些90年代的报纸上,我们偶尔会发现不同的字体会被混用,因为不是所有的字体都支持GBK标准,当遇到不支持的字的时候,有时人们会选择类似的字体替代不支持的字(比如用宋体替代仿宋体),而非额外造字。
在20世纪80年代末到90年代初的时候,我们今天所说的互联网还没有被广为人知。但在当时,美国和加拿大的大专院校已经普遍接入名为Usenet的计算机网络。一些中国留学生也得到了使用Usenet网络的机会,并开始试验在其上传输中文信息。这一试验促使他们开发了一种可以在使用7-bit ASCII编码的Usenet网络上传输GB2312信息的新编码,即后来的HZ编码(HZ即“汉字”的拼音缩写)。
使用GB2312编码的中文信息通常无法直接在Usenet上传输,原因是许多大型主机都不支持 8-bit扩展ASCII编码,例如IBM大型机就普遍使用EBDIC编码。虽然有一些程序可以在EBDIC和ASCII之间进行转换,但通常只有7-bit标准ASCII字符是可以完整转换的,而8-bit扩展ASCII编码的信息则可能在这种转换中被打乱。
HZ码对基于GB2312的中文信息进行了变形。它把GB2312编码信息种每个字节的第一位删除。因为所有的汉字代码的第一位都是以1开头的。而为了区分一段文字中的汉字部分和ASCII部分。它使用波浪线“~”作为转义序列。时至今日,我们仍然可以在Google Group里归档的早期Usenet新闻组的文章中找到使用HZ编码的文本。
演示8:ZWDOS
为了在IBM PC上阅读从Usenet上下载的HZ编码信息,魏亚桂开发了ZWDOS,这个软件是通过网络分发的免费软件,因为它出现在HTTP协议和万维网流行之前,通常人们会在BBS和FTP服务器上下载它。ZWDOS是为显示内容而设计的,并没有捆绑中文输入法,也因此它不是一个完整的计算机中文解决方案,要用HZ编码发表中文文章,就要用转换软件把GB2312或Big-5编码的文件转换成HZ编码。
20世纪90年代初,在美国和加拿大留学的中国学生创建了第一份中文在线杂志《华夏文摘》,这份网络杂志通过Usenet网络的电子邮件系统发行,也让HZ编码和ZWDOS在当时的中文网络用户中流行起来。
同时,Usenet上的alt.chinese.text(ACT)新闻组成为网络上第一个汇集了来自大陆、港澳台和海外各地不同背景的华人社群的中文舆论广场,深刻的影响了早期的中文互联网社区的形成。
关于在20世纪80年代到90年代的中文系统值得讨论的事情还有许多。在90年代中后期,除了GBK标准之外,由于计算机硬件资源正在快速增长,Unicode也开始流行。微软从Office 97开始加入对Unicode的支持,从此我们可以在一个文件中同时包含中文与其他非拉丁字母的语言,如希伯来语和泰语,这些语言也有着迥异于拉丁字幕的复杂的书写系统。
GBK 并不在所有的情况下都与GB2312兼容,特别是在那些大量使用ANSI Art菜单的BBS系统中,我将在后面展示一下Windows 95对GBK的支持是如何干扰BBS系统正常显示的。
接下来我会展示Palm OS。它是90年代末到2000年代初非常流行的移动操作系统,许多早期的移动互联网应用都建立在它上面。与后来的移动系统如Windows Mobile、iOS和Android相比,它对中文用户不是很友好。在Palm上的出现乱码的情况明显多于之后流行的移动操作系统,特别是在2000年代末UTF-8开始流行之后,Palm OS的限制对它的使用者的影响也越来越明显。
中国的寻呼系统使用的是一种改良版的POCSAG系统,这一标准在2000年标准化(即YD/T 1053-2000 信息寻呼网络数据传输协议)。它对中文进行编码的方式与HZ相似,都是将GB2312的第一位切掉,但寻呼系统并没有使用“~”起始的序列,而是使用Shift-in(0x0F)和Shift-out (0x0E)ASCII字符在中文和ASCII字符之间切换。
演示9: 使用GBK编码导致的ANSI Art乱码
这个演示中我会运行北京天堂资讯站BBS的备份。这个备份制作于1998年。Windows 95有两种方式来运行MS-DOS方式,一种是带有GBK字符支持的窗口模式。我们可以看到GBK字符显示没有任何问题。但是在这种模式下,BBS的菜单却显示出许多乱码。
Windows 95的另一个运行MS-DOS程序的方式则是全屏模式,在这个模式下Windows 95同样也提供了中文支持。但与窗口模式下的中文支持不同,全屏模式下的MS-DOS方式的中文支持是使用被称为PDOS95的外挂中文系统实现的,类似于之前提到的2.13和UCDOS,它只支持GB2312,但也因为如此,这个模式下BBS菜单比窗口模式中显示得更好看。
其实在BBS流行的那段时间,最受欢迎的中文系统是天汇(Tway)汉字系统,在天汇系统下,BBS菜单的效果相当漂亮。
演示10:使用CJKOS的PalmOS掌上电脑
最后一个演示的,是我研究中文编码与汉化的出发点,也就是Palm OS。CJKOS是中国大陆最流行的Palm OS外挂中文系统,它的开发者是杜永涛,我记得他是一位来自广州的开发者。CJKOS不仅提供了汉字显示和输入功能,而且还提供用户界面的本地化。这意味着它可以实现完整的中文掌上电脑体验。2002年,Palm公司正式进入中国大陆市场的时候,就没有像日文版Palm OS那样开发中文版Palm OS,而是将CJKOS与英文版本的Palm OS捆绑销售。
CJKOS只有GB和GBK版本,除了Palm智能手机的短信功能可以支持UCS-2编码之外,它没有更多针对Unicode的支持。在这个演示中,我会尝试打开百度首页,但由于百度已经转用UTF-8编码,所以Palm无法正确显示该网站。之后我会打开我自行设立的PDA网站“小可怜网”来演示早期的中文移动网站是如何工作的,这个网站使用的是GB2312编码。因此我们可以看到它在Palm和CJKOS上显示得非常好。看到这个画面让我觉得特别开心,因为它和我在2003年或2004年所体验到的事情场景是几乎完全一致的,在那个时候,我第一次尝试用Palm和带有蓝牙功能的手机访问到原始的移动互联网,而那种兴奋直到现在我还记得,因为那正是今天移动互联网的起点。
谢谢大家!