
作者:蓬岸 Dr.Quest
知乎文章编号:30640458
创建于:2017-12-03 3:39:11
修改于:2017-12-03 10:58:23
在今年六月份波士顿举办的@party上,来自MIT的程序写作专家Nick Montfort向参与者介绍了电脑生成书籍的现状,程序写作(Program Writing)和电脑生成文学(Computer-Generated Literary Art)并不完全等同于大众所理解的人工智能写作,作为结合了生成艺术(Generated Art)和文学的交叉学科,它收到了网络文学、乌力波、信息主义等文学现象的影响,而人工智能,也正在成为这一领域中极其重要的研究工具。
讲座中展示的这些图书都是由电脑程序写作完成的
there is no answer to this order of reasoning, except to advise a little wider perception, and extension of the too narrow horizon of habitual ideas. (or there is an answer to this order of reasoning.)
“这种推理没有答案,除了建议更广泛的感知,和拓宽狭隘的既有观念的视野”(或许这种推理会得到解答)
——某算法
标题图片:https://www.flickr.com/photos/nonstandardstudio/16121787737
今年早些时候,《华尔街日报》发表了一篇文章,这篇文章带有一个互动侧边栏,包括了一系列金融投资研究报告的片段。网站会提醒读者那一段摘录是由机器人完成的,而又有哪些是由人类完成的。诚然,《华尔街日报》对简练文风的偏爱让这种挑战更加可行。其中的一句话这样说到:“第二季度的现金结余8.3亿美元,这意味着在第一季度减少1.4亿美元之后,第二季度又消耗了8000万美元”。(Q2 cash balance expectation of $830m implies ~$80m of cash burn in Q2 after a $140m reduction in cash balance in Q1),这句话实际上只包含了三个数据点,并使用特定的语法合并在一起,而且不包含任何巧合的成分。像记者这样的白领工作者可能还未必需要担心他们的饭碗(至少现在是这样……),因为虽然新的自然语言生成(NLG)算法已经可以很好的在叙事文体中表达结构数据,但目前而言仍然不够完善。这实际上是一种相当强大的能力,因为对于我们来说,从数据中获得观点的本领往往依赖于数据的表现形式(比如说以图表展现的数据可能会让我们漏掉某些特定的数据行或列)。而这与无中生有地创造一个世界所需地胆量相差甚远。
自然语言生成算法通常会被归类于“人工智能”或“机器智能”地某种形式,因为它们所做地事情——比如编写体育新闻或天气预报稿件,亦或是编写房地产广告,就像我在快进实验室(Fast Forward Labs)的同事们所做的原型那样——而之前这些事情只有人类能做到。(在另外的文章里我会探讨人工智能的历史,以及Nancy Fulda等人所支持的相对概念)。
正如《华尔街日报》的文中所述,大多数人对自然语言生成算法的评价都类似于André Bazin的评价:以现实主义作品的角度来看它缺乏技巧,而以算法艺术的角度来看它又不够自动化。而商业化会将自然语言生成算法向着更写实的方向推进,因为投行和福布斯这样的通讯社不会花钱购买机器智能来生成文风怪异的稿件。反之,因为我们以人类的视角去评判机器智能,因此会将开发者向着更接近人类文风的方向推进。
但是如果我们将机器生成文本的目标设定为另外一种风格呢?或者,我们不是以人类的标准去评判(机器生成的文本),而是以其差异化去评判呢?其实机器或许生成我们人类无法创造的东西——或者会自行创造——以至于摆脱算法的帮助呢?自动写作是否有可能颠覆我们对自动化的理解,就像什克洛夫斯基(Shklovsky,俄国形式主义学派的创始人)在《作为技巧的艺术》(Art as Device)所描述的诗歌那样,为我们的创造力提供新的载体呢?

2014年NaNoGenMo参赛作品《Seraphs》,作者Liza Daly
Github链接:https://github.com/lizadaly/nanogenmo2014
这种利用自动化工具寻找新奇体验的过程正是全国小说生成月NaNoGenMo(National Novel Generation Month)的魅力所在,网络艺术家Darius Kazemi在2013年11月灵光乍现似的创办了NaNoGenMo这一一年一度的写作机器人峰会。出于对文学形式的思考,Kazemi开玩笑似的沿用了国家小说写作月NaNoWriMo(National Novel Writing Month)中仅有的两条规则:作品必须在30天内完成(11月份)而且至少要写够五万字。这种不拘一格的创作要求启发了新的创作试验:既然你可以编写某种可以创作小说的算法,那么为什么还要自己写小说呢?他将这一想法发表在推特上,并创建了一个新的GitHub(一个基于网络的软件开发协作工具)社区。
NaNoGenMo的官方Github:National Novel Generation Month
与NaNoWriMo类似,NaNoGenMo对所有人开放,而唯一的限制条件就是五万字的字数要求,也正因如此,NaNoGenMo逐渐成为一种使用算法试验文学形式的复合艺术运动。而这一团体的身份认同的形成一部分来自于对外界批评的反抗,许多批评者称他们的作品为“入不了出版商法眼”的“混乱的机器人脚本”。去年,一位参与者自嘲道“向普通人解释我们做所的事情是徒劳的。”而积极的一面则是他们正在通过共享优质的关键资源来构建群体的认同感。John Ohno(别名enkiv2)发布了可以生成六节诗、俳句和同义词的代码。而Allison Parrish(别名aparrish)则共享了其针对卡耐基梅隆大学发音词典(Carnegie Mellon Pronouncing Dictionary)开发的接口,这一接口可以为针对特定单词生成押韵词字典。最终Isaac Karth(别名ikarth)向成员们揭示了这种利用既有文本重新组合成的诗歌背后的理性根源——达达主义、威廉·巴勒斯(William Burroughs)的剪切技巧、以及乌力波(Oulipo)面向约束(constraint-oriented)的作品。当我与Kazemi讨论这一项目的时候,他表示肯尼思·戈德史密斯(Kenneth Goldsmith)的《不创意写作》激发了他针对如何让NaNoGenMo挑战人们对创作和创意的传统认知的思考。
技术限制解释了为什么NaNoGenMo需要将自己和意境重构(recontextualization)和重组的诗学相结合。实际上真正的自然语言生成算法,就是那些可以构建单词和语法、并切能够随着时间的推移变得更加智能的算法仍然处于非常早期的阶段,2014年大多数的作品都是使用创造性的规则转换已有的文本,这也导致了作品的相似性。

《搜索者》的部分文本,Github链接:thricedotted/theseeker
在2014年至少有两个作品使用了梦幻般的方式去探索机器智能的奇特美感。Thricedotted的《搜索者》(The Seeker)是一本试图“通过阅读WikiHow来了解人类行为”的机器的自传。这一作品充满着视觉美感,每一次算法操作的循环都会被抽象的雨点和类似“想象没有一件事情是没有方向的。”(imagine not one thing could be undirected.)这样的格言所标注。就像科塔萨尔的《跳房子》中跳房子游戏的暗喻一样,这些格言鼓励读者去感知随机数据中有意义的部分(Thricedotted的网络账号常常提到要“脑补”(apophenia))。电脑算法周而复始的重复着“工作、扫描、想象”的循环,不断地抓取WikiHow的内容,并针对工作中遇到的概念去搜索完全由文本构成的记忆,由此构建一个梦境的序列——或“抽象概念”(univision)——来理解它所不知道的概念。这些概念包含了最令人惊讶的诗歌作品,其美感源于阅读者不自主的从中获取的片段式的意境。
univision: change
(required evolutions suddenly concentrating favourable structures. a chemical behind conclusions. determining the opinion in the event. looking while happening. reciting the literature on the water. the position, existing. the amount around the resource. the task in the example. the selection near attempts. undergoing the layer and observing the object. the timeliness around the availability. Beginning memories…)
概念:改变
(需要进化突然集中有利的结构,结论背后的化学反应。 确定事件中的意见。 在发生时观看。 背诵有关水的文献。 存在的位置。 资源周围的金额。 在这个例子中的任务。 接近尝试的选择。 正在经历的层和观察对象。 与可用性相关的及时性。 开始回忆...)
Allison Parrish的《我在清水中淌过》(I Waded in Clear Water)则使用了情绪分析算法,它根据文本的情绪特征对其进行分级,并据此规则解释并改写古斯塔夫斯•H•米勒(Gustavus Hindman Miller)的《10000个梦的解释》(Ten Thousand Dreams)。Parrish依靠米勒书中公式化的“行为”+“含义”(action + denotation)结构(如 行为:“看到橡树结满橡果”,含义:“意味着升职加薪”)。她首先将行为部分转换为第一人称,简单的将句子重新处理(如“我看到橡树结满橡果”)然后根据情绪分析算法所得出的结果,将“含义”部分按照从梦中最坏到最好的顺序重新排列。情绪分数创建了短的章节比如:“我将车开到浑水中。我看到别人在除草”,和由一系列不相干的行动组成的长章节:“我走下一层楼梯。我看到一个瘸子。我看到我的爱人喝鸦片酒解愁。我听见嘲笑声。我停在窗台。我身上有虱子。我看到。我丢掉了它。无论如何我都感到忧郁。我发出一条信息……”根据情感算法,在清水中淌过是最好的梦。
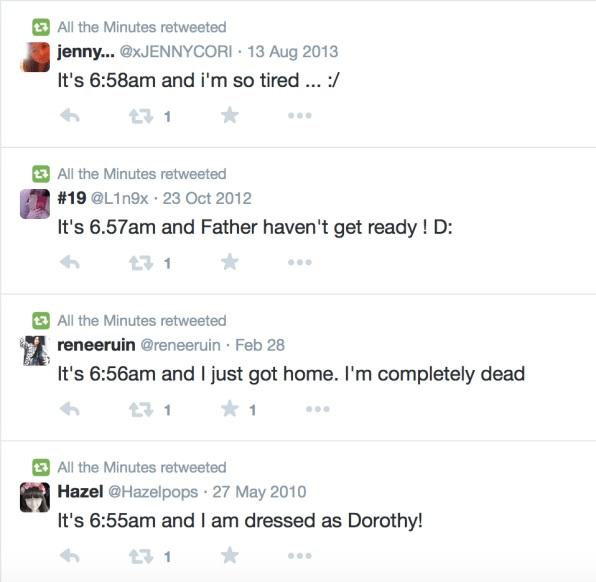
Moniker的推特机器人:@alltheminutes https://twitter.com/alltheminutes
另外一些作品则是对推特信息的重组,阿姆斯特丹的Moniker设计工作室编写了一个针对推特信息的简单查询,它搜索类似“这是 + 点 + 分 + 上午/下午 + 和 + ”这类结构的句子,构成一份包含全球日常活动的日记。这种“这是几点和我是”的结构倾向于提取可预测的陈述或牢骚,而展示出程序是如何自动化的获得我们的想法的:“这是12:29而我需要点饮料”“这是1:00pm而我还没有离开我的床”“这是11:00pm我终于得到了一杯咖啡。”《推傲慢与推偏见》(Twide and Twejudice)将奥斯汀原文中的对话以推特中相似内容的用词来替换,让对话看起来“更接地气”:(贝内特先生向贝内特太太打听宾利先生的事情)“他摆脱单身了吗?(Is he/she overrun 0r single?)”(贝内特太太对宾利先生的到来感叹道):“对我家傻妮们来说这真是太TMD好了(What _a fineee thingi 4my rageaholics girls!)”虽然这些作品不像《搜索者》那么复杂,但它通过将推特中的用词掺杂进奥斯汀的作品这种方式,展现了当代媒体是如何改变传播规范的。
这让我们回到了我们对电脑生成文本进行评判的依据的那个假设:以文章是否读起来像人类作品作为评判电脑作品的依据是迂腐的,因为什么样的语言能够被称作“自然语言”的标准是相对的,而不是绝对的。我们自身的语言习惯是通过与其他人的互动而建立的,这其中可能包括了特定的社会阶层,同事和同学,乃至在我们的推特时间线上乱发垃圾信息的机器人。在Medium网站近期的一篇文章中,Katie Rose Pipkin 有力的解释了机器是如何改变、并且已经改变了我们对自然语言的思考。无论我们承认与否,我们面对搜索工具和虚拟助手所使用的语言已经与其他情形下有所不同,因为我们已经潜移默化的开始理解它们的工作方式,并调整我们请求的方式以提高沟通效率。
机器学习领域的最新进展已经可以让机器发展出与我们类似的学习模型,不断地个更新它们所表达的信息和表达的方式来适应我们的输入。Kazemi正计划在2015年的NaNoGenMo作品中加入这种新的人机交流形式,让人和算法一起“合作”小说,算法会起草十个句子,然后他作为人类从中选择他认为最好的那句。“那么究竟是谁写成了这本书呢?”他回答道:“(电脑算法)写作了文章中的每一个字,而(我)则决定了正本小说的形式。”这种互动与基于IBM Watson构建的,面向律师和医生的新研究工具非常类似:ROSS是一款基于Watson API的法律工具,它可以展示特定问题的若干答案,而律师所要做的则是选择他们最喜欢的答案。如果NaNoGenMo可以帮助我们更加深刻的思考这种人机互动,可能会为未来的人工智能研究带来新的视野。